
CVPR 2026 Workshop
Now
I am building real Visual Intelligence, way beyond language and human perception.
I'm also Kaggle Grandmaster at H2O.ai, and Chief Scientific Advisor at Foundation CIDAUT in Spain working with brilliant students.
2025 Ph.D.
I finished my Ph.D. in Computer Science (summa cum laude) at the University of Würzburg, advised by Prof. Radu Timofte. Dissertation: Photorealistic and Controllable Neural Image Processing. Final Bosses: Ming-Hsuan Yang, Lei Zhang, Jirí Matas.
2022 – 2025
I joined Sony PlayStation, where I was a Computer Vision Scientist on Super-Resolution and AI Graphics Enhancement (like NVIDIA DLSS).
2022 M.Sc.
M.Sc. in Computer Vision from the Autonomous University of Barcelona (UAB), with honours for Real-time Photography Enhancement, advised by Dr. Javier Vazquez-Corral and Prof. Michael S. Brown (Samsung).
2020/21
I worked at Huawei Noah’s Ark Lab (London) and received the best intern award for my work on camera ISPs, supervised by Dr. Eduardo Pérez-Pellitero.
CVPR 2026 Workshop

CVPR 2026 Workshop

ICCV 2025 Tutorial

BMVC 2025 Workshop

InstructIR ECCV 2024

Sony PlayStation
My research aims to achieve real AI Visual Intelligence and Super-human perception. I replace the eyes with cameras and the brain with a computer.
My current research interests include deep learning, low-level computer vision, computational photography, imaging, and vision-language models.
Representative papers are highlighted — check my Google Scholar for the complete list.
|
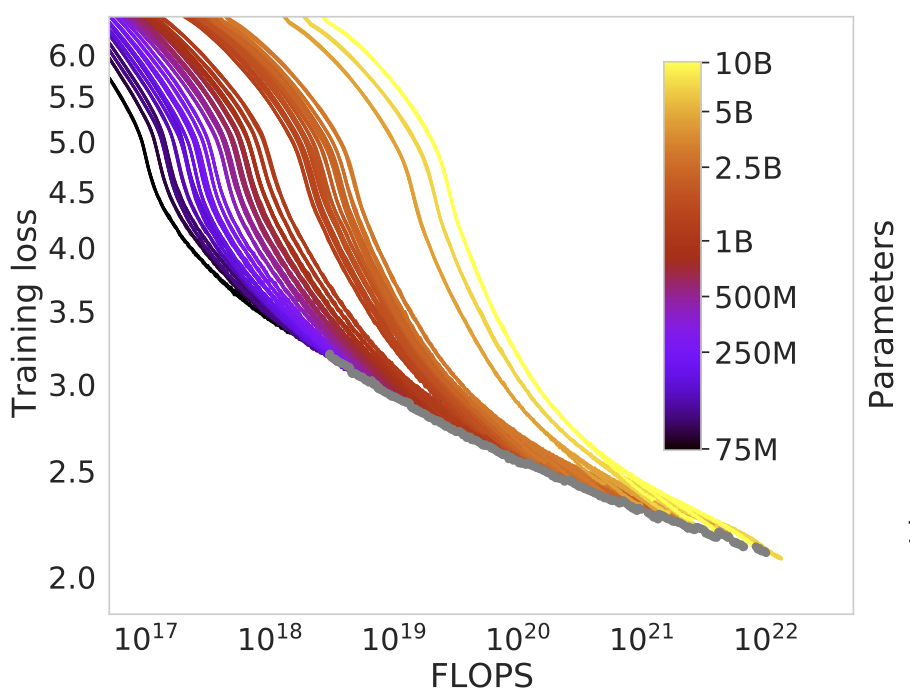
JOURNAL PREPRINT · 2026 Efficient Image Restoration Using Deep Learning: A SurveyA survey of efficient deep learning methods for image restoration, covering architectures, training strategies, and practical deployment for real-world restoration pipelines. |
|
JOURNAL PREPRINT · 2026 · NTIRE CHALLENGE RealX3D: A Physically-Degraded 3D Benchmark for Multi-view Visual Restoration and ReconstructionProject / arXiv / NTIRE 2026 Challenge / Video RealX3D is a real-capture 3D benchmark for restoration and reconstruction under in-the-wild degradations — low-light, blur, occlusion, reflection, etc. |
|


|
CVPR · 2026 · LOVIF WORKSHOP Towards Unified Image Deblurring using a Mixture-of-Experts DecoderDeMoE is the first all-in-one deblurring method that restores images with diverse blur types — global motion, local motion, low-light blur, and defocus. |


|
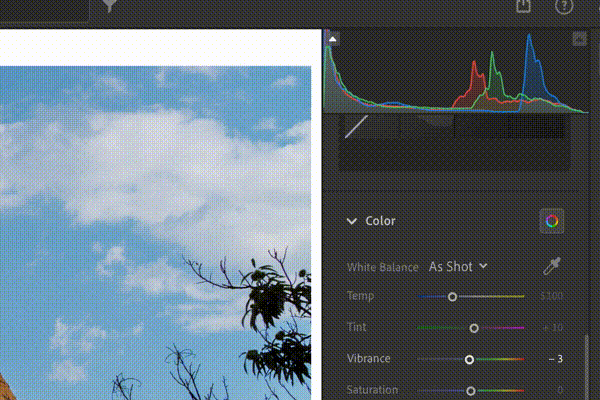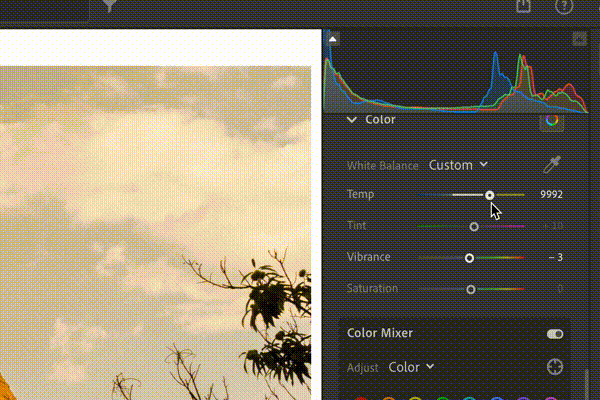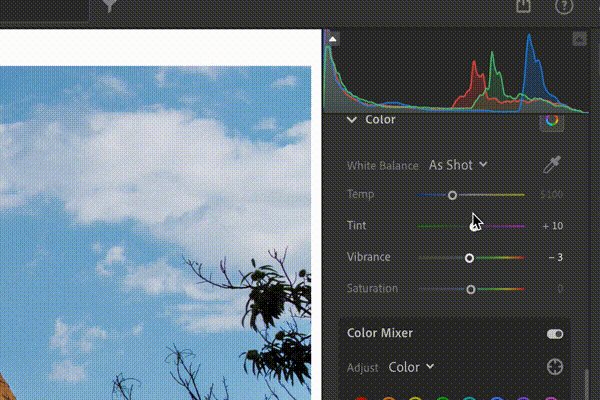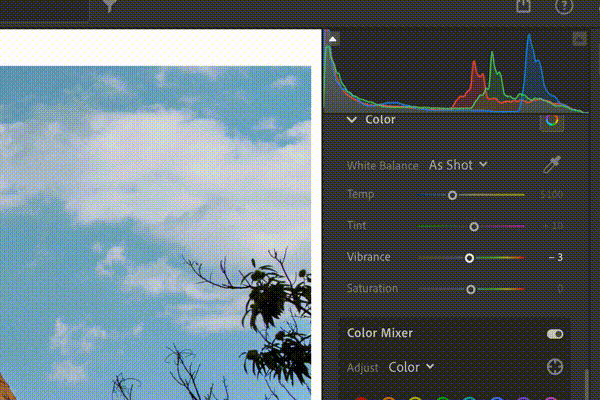
WACV · 2026 INRetouch: Context Aware Implicit Neural Representation for Photography RetouchingA context-aware implicit neural representation that learns professional retouching from before–after pairs and transfers complex Lightroom-style edits to new images with a single example. |


|
arXiv · 2025 FLOL: Fast Baselines for Real-World Low-Light EnhancementFast and efficient baselines for real-world low-light image enhancement. Process HD videos at 24 FPS. Fastest model in NTIRE challenges. |
|
ICCV · 2025 PixTalk: Controlling Photorealistic Image Processing and Editing with LanguageWe propose the first approach that introduces language and explicit control into the image processing and editing pipeline. PixTalk is a vision-language multi-task image processing model, guided using text instructions. Our method is able to perform the most popular techniques in photography. |

|
ICCV · 2025 Bokehlicious: Photorealistic Bokeh Rendering with Controllable AperturesarXiv, Code and Models upcoming The best Bokeh rendering method using neural networks and a novel dataset. The neural model allows to control the apertur from f/16 to f/1.8 |


|
ICCV Workshop · 2025 Extreme Compression of Adaptive Neural ImagesWe present a novel analysis on compressing neural fields, with the focus on images. We also introduce Adaptive Neural Images (ANI), an efficient neural representation that enables adaptation to different inference or transmission requirements. |


|
CVPR · 2025 DarkIR: Robust Low-Light Image RestorationDarkIR In low-light conditions, you have noise and blur in the images, yet, previous methods cannot tackle dark noisy images and dark blurry using a single model. We propose the first approach for all-in-one low-light restoration including illumination, noisy and blur enhancement. |
|
ECCV · 2024 InstructIR: High-Quality Image Restoration Following Human Instructionsproject page / GitHub / arXiv / Video / Twitter X / Demo 🤗 InstructIR takes as input a degraded image and a human-written instruction for how to improve that image. The (single) neural model performs all-in-one image restoration. We achieve state-of-the-art results on several restoration tasks including image denoising, deraining, deblurring, dehazing, and (low-light) image enhancement. |
|


|
ICIP · 2024 Streaming Neural ImagesImplicit Neural Representations (INRs) are a novel paradigm for signal representation that have attracted considerable interest for image compression. We explore the critical yet overlooked limiting factors of INRs, such as computational cost, unstable performance, and robustness |


|
ICIP · 2024 Toward Efficient Deep Blind RAW Image RestorationWe tackle image restoration directly in the RAW domain (yes, it is tricky and a bit crazy). |


|
ICIP · 2024 Simple Image Signal Processing using Global Context GuidanceFirst, we propose a novel module that can be integrated into any neural ISP to capture the global context information from the full RAW images. Second, we propose an efficient and simple neural ISP that utilizes our proposed module. |


|
AAAI · 2024 NILUT: Conditional Neural Implicit 3D Lookup Tables for Image Enhancementproject page / arXiv / GitHub & Demo / Video / Easter Egg NILUTs are neural representations of real 3D LUTs for controllable photo-realistic image enhancement and color manipulation. Moreover, a NILUT can be extended to incorporate multiple styles into a single network with the ability to blend styles implicitly. |


|
WACV · 2024 BSRAW: Improving Blind RAW Image Super-ResolutionarXiv / cvf Proceedings / GitHub We advance RAW sensor images up-scaling (Super-Resolution). We explore diverse image degradations (e.g. Noise, Blur) to emulate a low-resolution RAW image, and we train a neural network to upsample it. |


|
CVPR Workshop · 2023 Efficient multi-lens bokeh effect rendering and transformationpaper / cvf Proceedings / GitHub EBokehNet, an efficient state-of-the-art solution for Bokeh effect transformation and rendering. We can render Bokeh from all-in-focus images, or transform the Bokeh of one lens to the effect of another lens without harming the sharp foreground in the image. |


|
CVPR Workshop · 2023 Towards Real-Time 4K Image Super-Resolutionpaper / cvf Proceedings / GitHub The paper presents an exhaustive study of baseline methods for real-time image SR. The methods allow 60 FPS and even 120 FPS. |


|
WACV · 2023 · (Oral Presentation, Spotlight) Perceptual Image Enhancement for Smartphone Real-Time ApplicationsarXiv / cvf Proceedings / GitHub We propose LPIENet, a lightweight network for perceptual image enhancement, with the focus on deploying it on smartphones. The model was tested for image denoising, deblurring, and HDR correction. |


|
ECCV · 2022 Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and RestorationarXiv / eccv Proceedings / GitHub / Demo (3M runs!) Super-resolution of compressed images using transformers. We use the Swin Transformer V2, to improve SwinIR for image super-resolution, and in particular, the compressed input scenario. Using this method we can tackle the major issues in training transformer vision models, such as training instability, resolution gaps between pre-training and fine-tuning. |


|
ECCV Workshop · 2022 Reversed Image Signal Processing and RAW ReconstructionarXiv / eccv Proceedings / GitHub This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. |


|
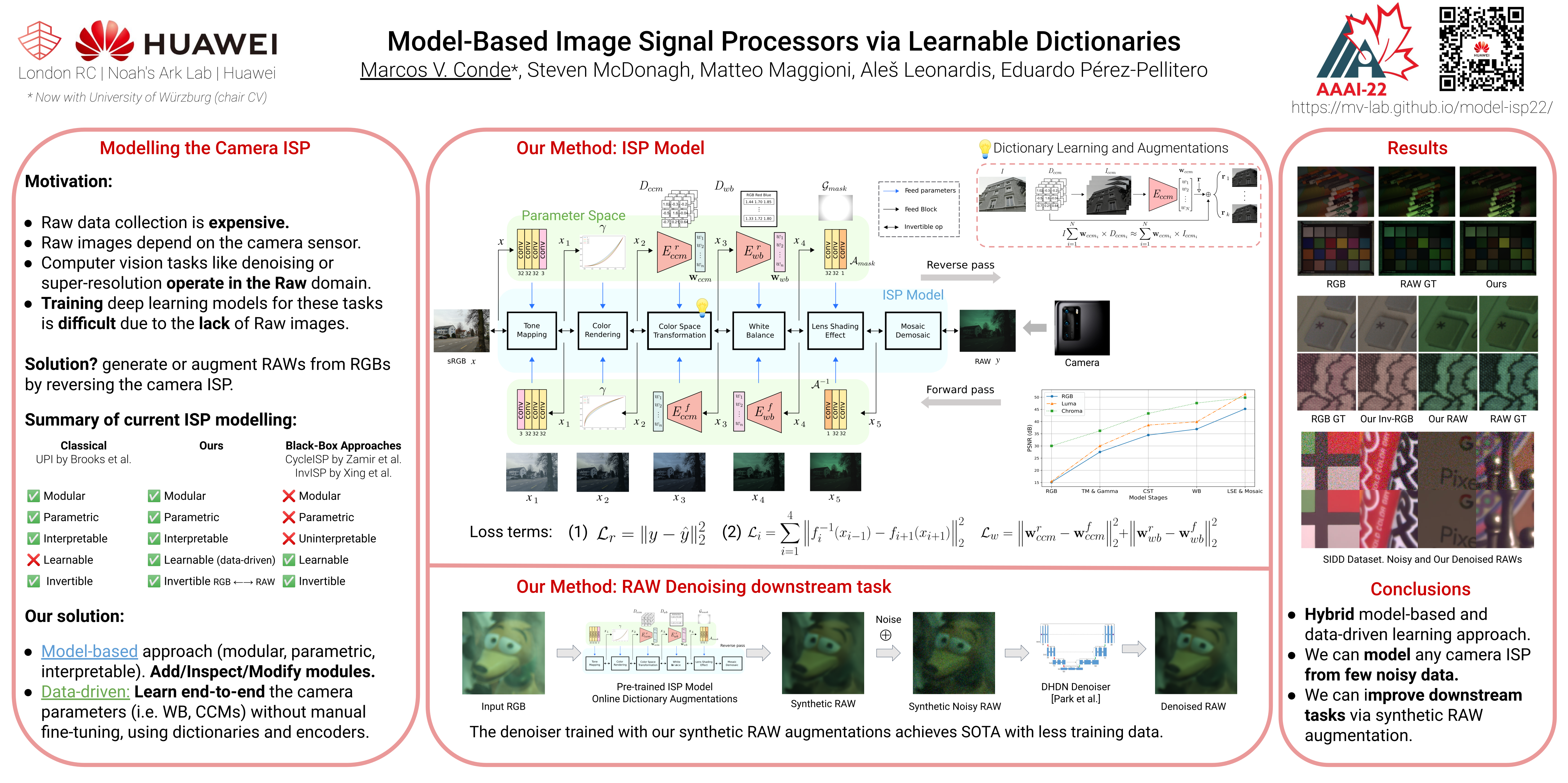
AAAI · 2022 · (Oral Presentation, Spotlight) Model-Based Image Signal Processors via Learnable Dictionariesproject page / GitHub / arXiv / Poster Hybrid model-based and data-driven approach for modelling ISPs using learnable dictionaries. We explore RAW image reconstruction and improve downstream tasks like RAW Image Denoising via raw data augmentation-synthesis. |

|
CVPR Workshop · 2021 CLIP-Art: Contrastive Pre-Training for Fine-Grained Art ClassificationarXiv / cvpr Proceedings / GitHub / Kaggle We were one of the 1st attempts to use CLIP (Contrastive Language-Image Pre-Training) for training a neural network on a variety of art images and descriptions, being able to learn directly from raw descriptions about images, or if available, curated labels. |
Academic ServiceReviewer: Outstanding Reviewer at ECCV 2024. CVPR 2022-2026, ECCV 2022-2026, ICCV 2023-2025, IEEE Transactions on Image Processing, IEEE Transactions on Computational Imaging, IEEE Transactions on Pattern Analysis and Machine Intelligence Workshops: AIM 2025 ICCV / NTIRE 2025 CVPR / AIM 2024 ECCV / AI for Streaming (AIS 2024) CVPR / NTIRE 2024 CVPR / VQEG 2023 / NTIRE 2023 CVPR / AIM 2022 ECCV |
Other Projects |
|
H2O Open Ecosystem for LLMs
We introduce a complete open-source ecosystem for developing and testing LLMs.
The goal of this project is to boost open alterna- tives to closed-source approaches.
|
|
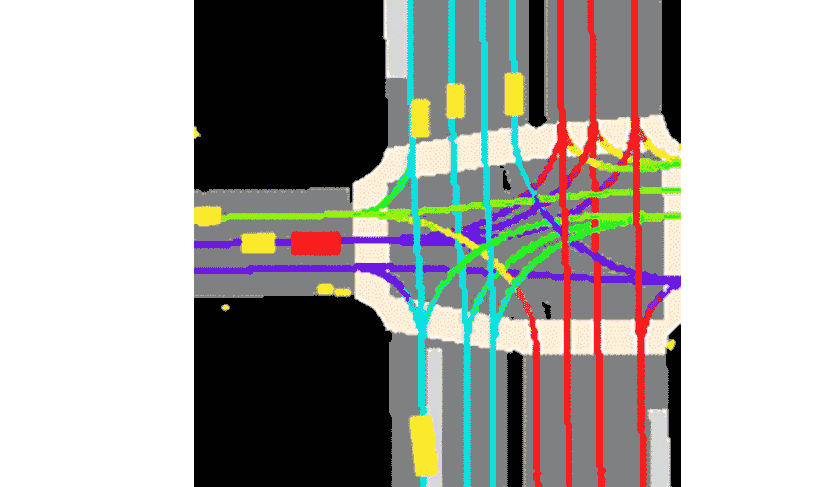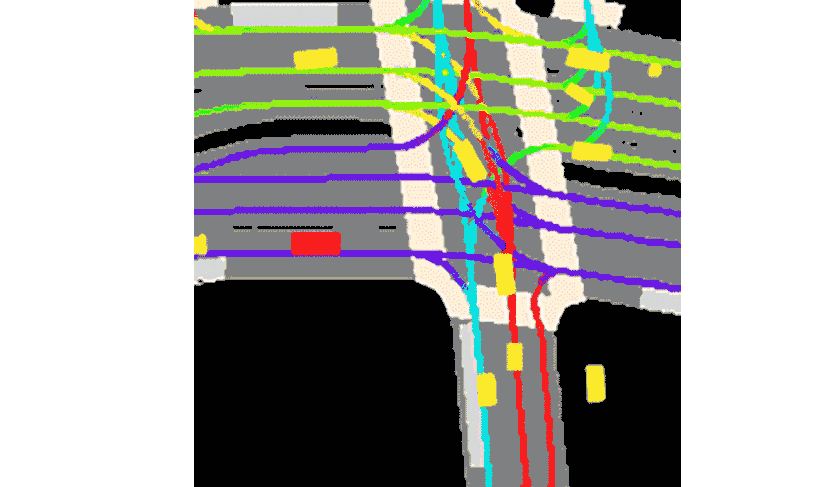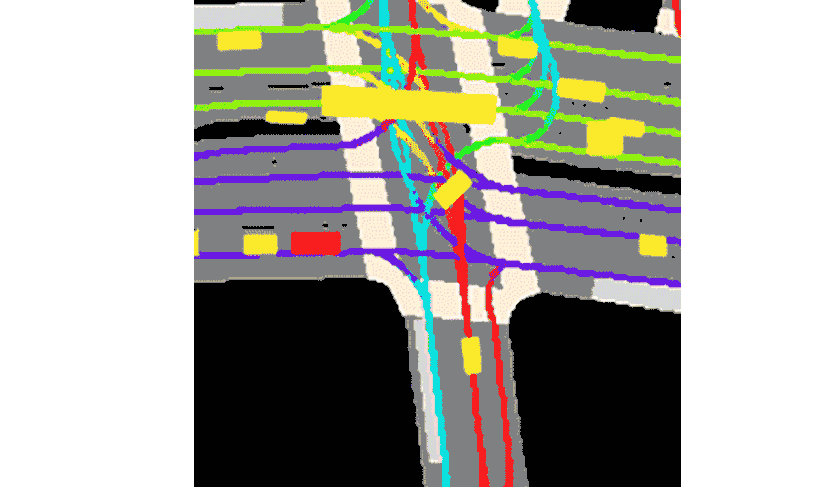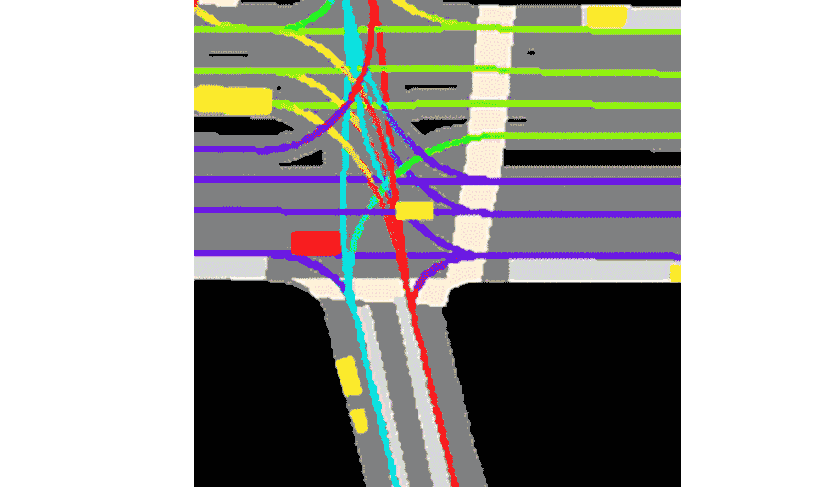
Motion Prediction for Autonomous Driving
We proposed multiple methods for motion prediction in Autonomous Driving.
The methods were presented at CVPR Workshops, ICRA, and IEEE Transactions on Intelligent Transportation Systems (T-ITS, Q1, IF:8.5).
|

|
Event-Based Eye Tracking - AIS Challenge CVPR 2024
This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye.
|

|
Kuzushiji Recognition (Nov. 2019)
I was invited by Japan’s National Institute of Informatics (NII) and ROIS-DS Center for Open Data in the Humanities (CODH)
to present a novel solution for the Kuzushiji Recognition Challenge
at the Japanese Culture and AI Symposium 2019 in Tokyo.
|
{kind=link}
{kind=link}
{kind=link}